Recently a developer came up to me and started asking questions about a problem he was experiencing with
a stored procedure he’d written to query a large table. He’d been looking at the execution plan and
noticed that the stored procedure was table scanning one of the tables that it was querying.
The query was fairly straightforward with two columns specified in the WHERE predicate, but the
table was large. He had quite correctly decided to create an index on those two columns. Surprisingly
this did not seem to resolve the situation as the stored procedure continued to table scan the table.
At this point he asked me to look at the problem.
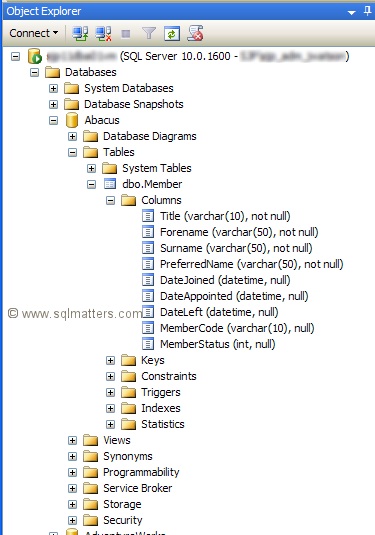
The first thing I did was to simplify the query as much as possible to make it easier to identify
the problem. Here is the table design and the simplified version of the query in the stored procedure
that caused the table scanning :
Query :
SELECT Title,Forename,Surname
FROM Member
WHERE DateAppointed<'23 Aug 2008' AND
DateLeft>'23 Aug
2008'
The index that he had tried was :
CREATE NONCLUSTERED INDEX idx1 ON dbo.Member
( DateLeft ASC,
DateAppointed ASC
)
Switching on the ‘Include Actual Execution Plan’, running the query and looking at the graphical output
in the ‘Execution Plan’ tab in SSMS confirmed that the query is table scanning :
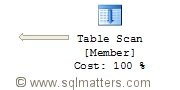
On the face of there was no obvious reason why the query should not have made use of this index. After
trying a few things and not succeeding in getting the query to use the index I decided to see what the
Database Engine Tuning Advisor (DETA) made of the query. At this point I suddenly realised what the
problem was – there was no primary key on the table.
The problem was that although the optimiser could use the index to identify the correct rows in the
table to meet the where condition, it would then have to go back to the table to get the columns
specified in the select statement, but it required a primary key on the table to be able to do that look up.
If this was a database we owned then we could have added a primary key, either by identifying an
existing column to use or to add an extra column and specifying it as an identity column. Unfortunately
it was a third party supplied database and it wasn’t practical to make structural changes.
The solution was to specify an index which had include columns covering the columns specified in the
select statement :
CREATE NONCLUSTERED INDEX idx_Member_1 ON
dbo.Member
( DateLeft ASC,
DateAppointed ASC
)
INCLUDE (Title,Forename,Surname)
This is the index specified by the DETA and resolves the problem because all the information is
contained in the index. This is because the INCLUDE clause contains all the columns in the SELECT
part of the query – no further look up is required on the underlying table and the execution plan
confirms that the query does indeed do an index seek using the new index :

All in all a neat solution to the problem in this instance, though I can’t help feeling that it would
still have been better to have had a primary key on the table in the first place.